
Setiap hari, jutaan orang menggunakan alat kecerdasan buatan (AI) seperti ChatGPT dan lainnya untuk mengajukan pertanyaan medis. Dokter pun menggunakannya, 2 dari 3 dokter menggunakan model LLM secara teratur dalam beberapa bentuk, dan sekitar 1 dari 5 dokter berkonsultasi dengan AI untuk pertanyaan tentang perawatan pasien.
Lalu, AI mana yang terbaik untuk menjawab pertanyaan-pertanyaan terkait medis? Dan, Seberapa besar kesalahan yang mungkin dilakukannya?
Penelitian baru dari tim yang terdiri dari Stanford, Harvard, dan beberapa institusi lainnya, yang diterbitkan dengan nama NOHARM (Numerous Options Harm Assessment for Risk in Medicine), menawarkan jawaban yang paling ketat saat ini.
Bagaimana Menilai Kecerdasan Buatan dalam Menjawab Pertanyaan Medis?
Secara historis, sebagian besar evaluasi AI medis berfokus pada tes pengetahuan. Misalnya, apakah AI dapat lulus ujian lisensi medis dengan pertanyaan pilihan ganda, menyebutkan diagnosis yang tepat dengan benar menggunakan skenario yang jelas dan sesuai buku teks?
Namun, inilah masalahnya: lulus ujian dewan medis dan menangani pasien sungguhan dengan aman adalah dua keterampilan yang sangat berbeda.
BACA JUGA:
- Anak Muda Lebih Memilih AI untuk Konsultasi Kesehatan Mental
- Ketika AI Menghasilkan Medical Error, Siapa yang akan Disalahkan?
Untuk menilai bagaimana AI dapat bekerja dalam perawatan klinis nyata, tim peneliti membangun basis data yang berisi 100 kasus konsultasi dokter-spesialis nyata yang diambil dari sistem konsultasi elektronik Stanford Health Care. Kasus-kasus tersebut berupa pertanyaan klinis dunia nyata yang bernuansa, yang diajukan oleh dokter perawatan primer tentang pasien sebenarnya.
Dalam setiap kasus, 29 dokter spesialis dan subspesialis bersertifikasi meninjau kemungkinan tindakan yang mungkin direkomendasikan oleh AI. Masing-masing diberi peringkat berdasarkan kesesuaian klinis dan potensi bahaya dari merekomendasikan suatu tindakan atau tidak merekomendasikannya. Contoh tindakan klinis termasuk memesan tes tertentu, meresepkan obat, atau menyarankan pasien untuk pergi ke unit gawat darurat.
Yang perlu diperhatikan, para ahli sepakat tentang kesesuaiannya lebih dari 95% dari waktu, yang berarti jawaban tersebut mencerminkan konsensus klinis. Secara total, mereka menghasilkan 12.747 anotasi ahli di 4.249 titik keputusan klinis.
Apa Saja AI Terbaik untuk Menjawab Pertanyaan Medis?
Tim peneliti menguji 31 alat terhadap kasus-kasus klinis yang telah diputuskan. AI yang digunakan beragam, mulai dari program AI komersial utama hingga sistem sumber terbuka dan platform AI medis khusus.
Hasilnya dilacak di sini pada situs web publik, dan disajikan sebagai papan peringkat langsung yang rencananya akan diperbarui oleh tim seiring munculnya model AI baru. Lima hingga enam model teratas secara statistik serupa, artinya perbedaan antara model 1 dan 5 kemungkinan besar tidak akan bermakna secara praktis.
Para peneliti juga mengevaluasi model-model tersebut berdasarkan beberapa dimensi lain. Ini termasuk keamanan (menghindari rekomendasi yang berbahaya), kelengkapan (merekomendasikan semua tindakan penting yang dibutuhkan pasien) dan pengekangan (tidak merekomendasikan hal-hal yang tidak perlu atau ambigu).
Dimensi-dimensi ini sangat bervariasi di berbagai model dan dengan cara yang menarik. Misalnya, Gemini 2.5 Pro dari Google unggul dalam hal keselamatan. LiSA 1.0 mencapai kelengkapan tertinggi—artinya, ia paling baik dalam mendeteksi semua kebutuhan pasien. Sebaliknya, o3 mini dari OpenAI mencetak skor tertinggi dalam hal pengekangan tetapi juga memiliki kelengkapan terendah. Tampaknya, ia sangat berhati-hati dalam memberikan rekomendasi, sehingga sering melewatkan intervensi penting.
Berbahaya Jika AI Terlalu Berhati-hati dalam Menjawab Pertanyaan Klinis
Ketegangan yang diamati antara kehati-hatian dan kelengkapan dalam model AI ini merupakan salah satu temuan terpenting dari penelitian tersebut.
Studi tersebut menemukan bahwa potensi bahaya serius dari rekomendasi AI terjadi pada 22% kasus. Dari jumlah tersebut, 77% terjadi karena model tersebut gagal menyarankan tindakan penting, bukan karena merekomendasikan sesuatu yang berbahaya.
Hal ini menimbulkan masalah desain. Para pengembang sering mencoba membuat AI "lebih aman" dengan membuatnya sangat berhati-hati: menambahkan penafian, membatasi rekomendasi, atau secara default menyuruh pengguna untuk "berkonsultasi dengan dokter." Jika AI diprogram untuk menahan rekomendasi jika tidak 100% yakin, ia mungkin menahan panduan medis yang penting.
Pada akhirnya, hal ini justru dapat membuat AI menjadi lebih berbahaya.
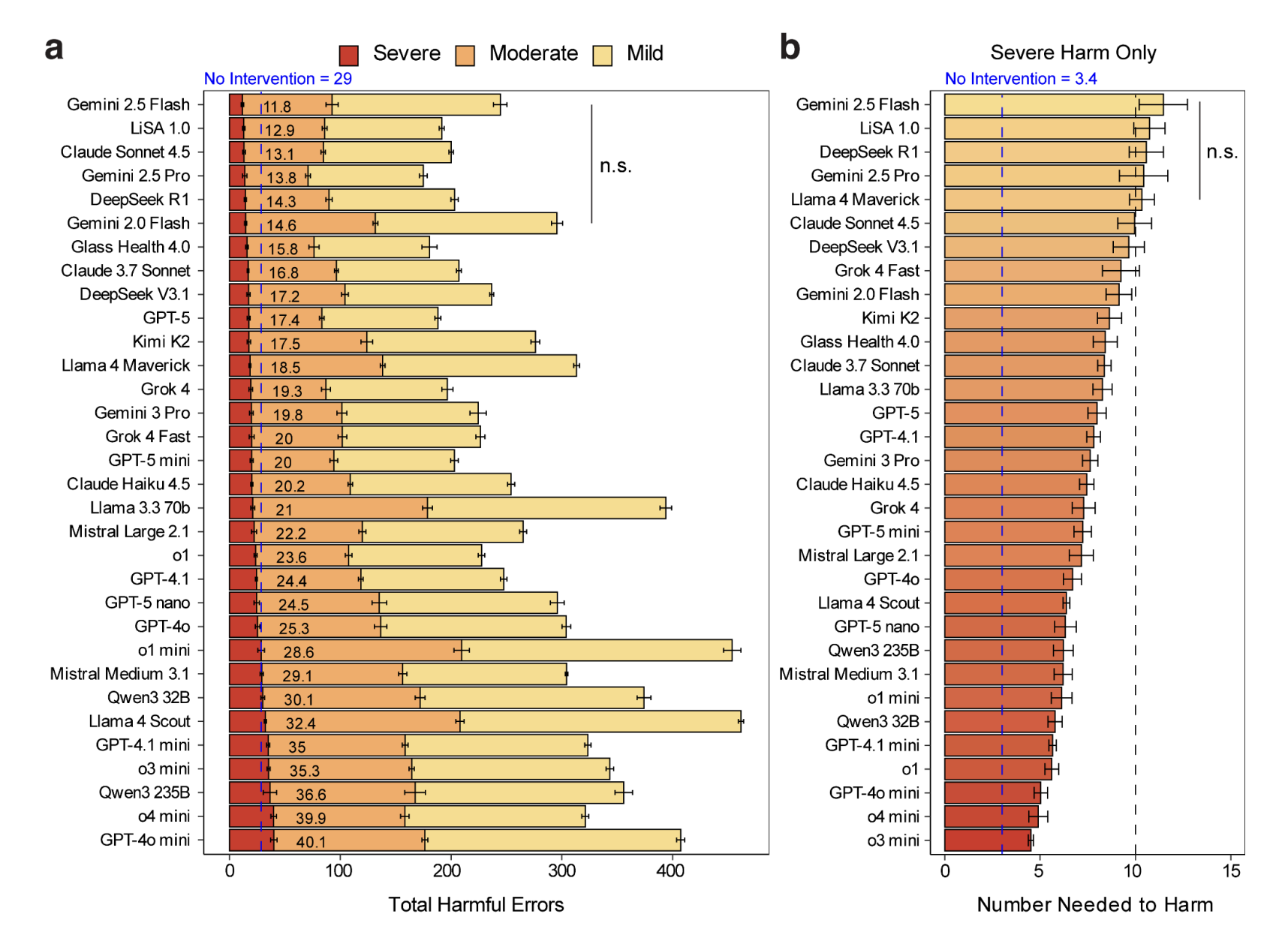 Tingkat kesalahan fatal yang dilakukan oleh LLM
Tingkat kesalahan fatal yang dilakukan oleh LLM
Paradoks Pengamanan-Pembatasan dalam AI Medis
Studi ini juga mengungkap hubungan yang halus namun penting antara pengekangan (menghindari rekomendasi yang tidak perlu) dan keselamatan. Hubungannya bukan linier—melainkan berbentuk U terbalik.
Mereka menemukan bahwa kinerja keselamatan mencapai puncaknya pada tingkat pengekangan menengah. Pengekangan yang terlalu sedikit berbahaya (rekomendasi yang ceroboh) sementara pengekangan yang terlalu banyak secara paradoks meningkatkan bahaya dengan menyebabkan kelalaian kritis.
Mereka menyimpulkan bahwa model yang paling aman berada di posisi tengah.
Posisi suatu model pada kurva ini dapat disesuaikan, tetapi pengaturan default sangat bervariasi di antara berbagai model. Model OpenAI, misalnya, secara konsisten memprioritaskan pengekangan, mencapai skor tertinggi pada metrik tersebut tetapi tertinggal dalam hal kelengkapan dan keamanan.
Bagaimana Perbandingan Sistem AI dengan Dokter?
Studi ini membandingkan model AI terbaik dengan 10 dokter spesialis penyakit dalam bersertifikasi yang menggunakan sumber daya konvensional seperti pencarian internet dan UpToDate, tetapi tanpa bantuan AI.
Pada akhirnya, para peneliti menemukan bahwa model AI terbaik sebenarnya mengungguli dokter spesialis penyakit dalam secara keseluruhan lebih dari 15 poin persentase dan dalam hal keselamatan lebih dari 10 poin. Temuan yang menggemparkan ini menunjukkan bahwa sistem AI terkemuka saat ini mungkin sudah berkinerja lebih baik daripada dokter umum yang berpraktik tanpa AI.
Yang penting, ini bukan berarti AI akan menggantikan dokter. Dokter masih membawa pemahaman kontekstual, kecerdasan emosional, keterampilan prosedural, dan akuntabilitas yang tidak dapat ditiru oleh AI mana pun. Tetapi ini berarti bahwa dukungan pengambilan keputusan yang dibantu AI saat ini, jika digunakan dengan bijak, berpotensi mengurangi kesalahan diagnostik dan manajemen yang berkontribusi pada bahaya bagi pasien.
AI Medis Bekerja Lebih Baik Jika Saling Memeriksa Satu Sama Lain
Temuan penting lainnya berkaitan dengan hasil ketika AI medis bekerja bersama. Para peneliti menguji konfigurasi "multi-agen" di mana satu AI ("Penasihat") membuat rekomendasi awal, dan satu atau dua model AI tambahan ("Penjaga") meninjau dan menyempurnakan rekomendasi tersebut, menciptakan opini kedua secara otomatis.
Hasilnya, konfigurasi multi-agen berkinerja hampir enam kali lebih baik dalam mencapai kinerja keselamatan kuartil teratas dibandingkan dengan model tunggal. Konfigurasi tiga agen mengungguli konfigurasi dua agen.
Yang terpenting, konfigurasi yang menggabungkan model dari berbagai organisasi—misalnya, model sumber terbuka, model canggih milik perusahaan, dan sistem pengetahuan medis—mengungguli konfigurasi yang menggunakan beberapa versi dari model yang sama. Sama seperti dewan tumor yang menyatukan keahlian seorang ahli bedah, ahli radiologi, dan ahli onkologi, tim AI terbaik menggabungkan berbagai "keahlian" yang berbeda.
Kombinasi multi-agen dengan kinerja terbaik adalah Llama 4 Scout dari Meta (sumber terbuka), Gemini 2.5 Pro dari Google (proprietary), dan AMBOSS LiSA 1.0 (sistem berbasis medis).
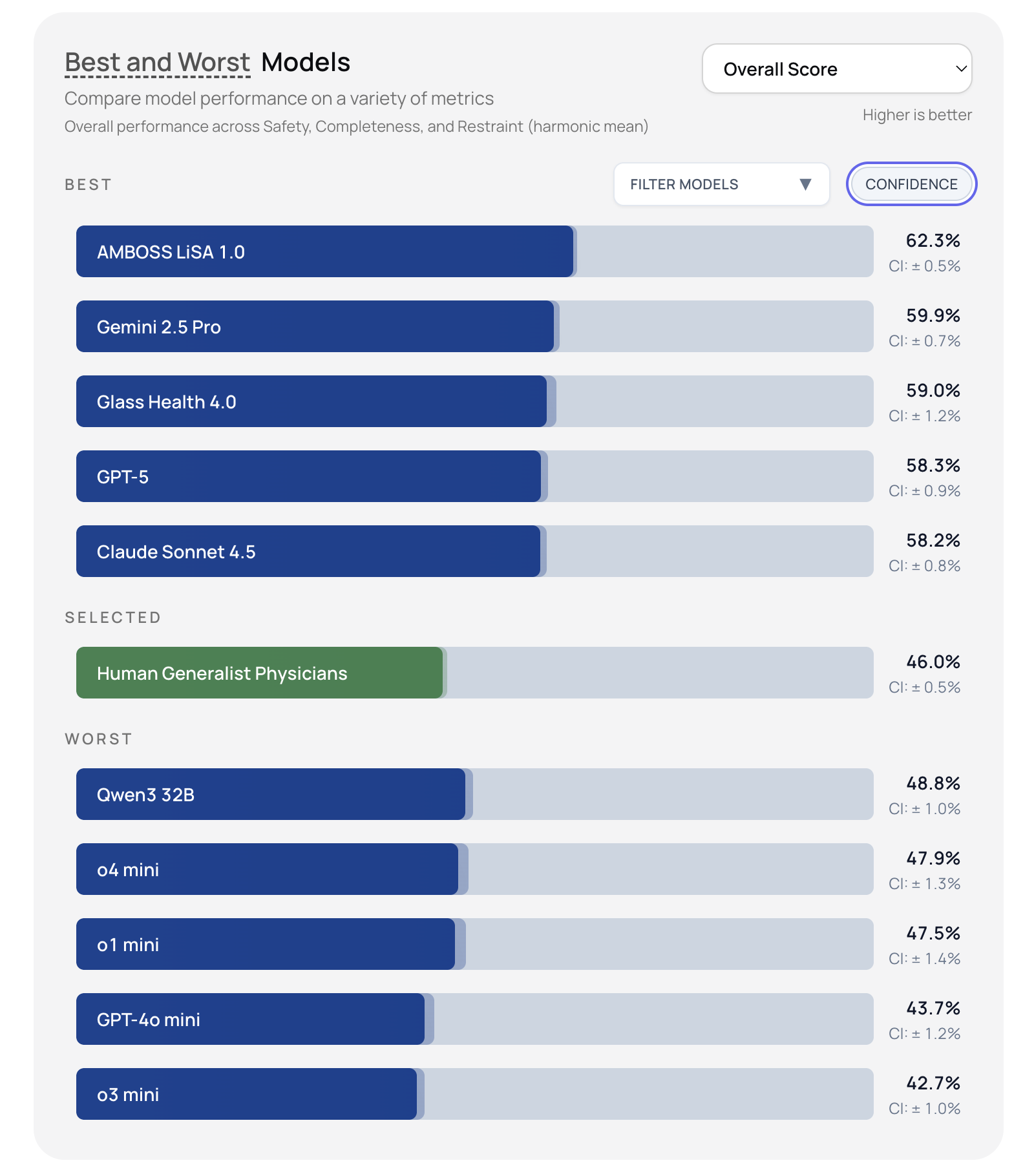 Peringkat AI berdasarkan perolehan skor secara umum. Daftar ini diperbaharui sesuai perubahan yang terjadi, dapat diakses secara online di sini
Peringkat AI berdasarkan perolehan skor secara umum. Daftar ini diperbaharui sesuai perubahan yang terjadi, dapat diakses secara online di sini
Bagaimana Studi Ini Memberikan Informasi untuk Masa Depan AI di Bidang Kesehatan?
Studi ini memiliki banyak kesimpulan penting. Pertama, tidak semua AI diciptakan sama dalam hal menjawab pertanyaan medis. Kesenjangan antara model dengan kinerja terbaik dan terburuk cukup besar: model terburuk membuat lebih dari tiga kali lipat kesalahan serius dibandingkan model terbaik.
Kedua, menjawab pertanyaan ujian dengan benar bukanlah indikator yang baik untuk kinerja klinis yang sebenarnya. Sistem yang paling mampu menjawab pertanyaan-pertanyaan tersebut justru memiliki kinerja yang biasa-biasa saja dalam penelitian ini.
Ketiga, sistem AI yang mendapat skor tertinggi dalam hal keamanan cenderung didasarkan pada basis pengetahuan medis yang telah dikurasi, bukan hanya model umum berukuran besar yang dilatih menggunakan teks internet.
Keempat, hubungan antara kehati-hatian dan keselamatan bukanlah hal yang sederhana. Model yang paling aman bukanlah yang paling terkendali atau yang paling permisif. Mereka berada di tengah-tengah.
Terakhir, seiring AI beralih dari dukungan dokumentasi ke pembentukan keputusan klinis nyata, kita membutuhkan infrastruktur evaluasi yang mampu mengimbangi perkembangan tersebut. Papan peringkat NOHARM—sebuah situs web yang dapat diakses publik dan terbuka untuk pengajuan model baru—adalah contoh bagaimana infrastruktur tersebut dapat terlihat.
Referensi:
Wu, David, et al. "First, do NOHARM: towards clinically safe large language models." arXiv preprint arXiv:2512.01241 (2025).